Goldratt's Dice Game
Paul Bayer, v03, 2020-09-14
Goldratt's Dice Game from his business novel "The Goal" is a classical illustration that dependencies and statistical fluctuations diminish the throughput through a system.
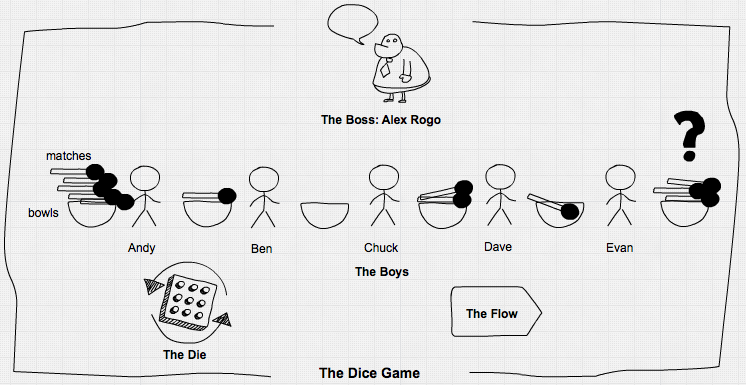
Alex Rogo, the hero of the novel plays a game with five boys:
While they go get the others, I figure out the details. The system I've set up is intended to "process" matches. It does this by moving a quantity of match sticks out of their box, and through each of the bowls in succession. The dice determine how many matches can be moved from one bowl to the next. The dice represent the capacity of each resource, each bowl; the set of bowls are my dependent events, my stages of production. Each has exactly the same capacity as the others, but its actual yield will fluctuate somewhat.
In order to keep those fluctuations minimal, however, I decide to use only one of the dice. This allows the fluctuations to range from one to six. So from the first bowl, I can move to the next bowls in line any quantity of matches ranging from a minimum of one to a maximum of six.
Throughput in this system is the speed at which matches come out of the last bowl, Inventory consists of the total number of matches in all of the bowls at any time. And I'm going to assume that market demand is exactly equal to the average number of matches that the system can process. Production capacity of each resource and market demand are perfectly in balance. So that means I now have a model of a perfectly balanced manufacturing plant.
Five of the boys decide to play. Besides Dave, there are Andy, Ben, Chuck, and Evan. Each of them sits behind one of the bowls. I find some paper and a pencil to record what happens. Then I explain what they're supposed to do.
"The idea is to move as many matches as you can from your bowl to the bowl on your right. When it's your turn, you roll the die, and the number that comes up is the number of matches you can move. Got it?"
They all nod. "But you can only move as many matches as you've got in your bowl. So if you roll a five and you only have two matches in your bowl, then you can only move two matches. And if it comes to your turn and you don't have any matches, then naturally you can't move any."
Eliyahu M Goldratt: The Goal.– 3rd ed, p. 105
Then Rogo explains to the boys that with the die on average they should pass 3.5 matches through the system, so after twenty cycles they should have got an output of seventy.
An assembly line
As Goldratt described it, the game is done in a fixed cycle – no asynchronism here and no need for a discrete-event-simulation. But more realistically it could be seen as an assembly line with buffers between the five workers:

The workers take on average 3.5 time units for processing an item and they are admonished to work as fast as possible. To implement it, we need some data structure for workers …
using DiscreteEvents, Distributions, DataFrames, Random
mutable struct Worker
nr::Int64 # worker number
input::Channel
output::Channel
dist::Distribution # distribution of processing time
retard::Float64 # worker retard factor, 1: no retardation, >1: retardation
done::Int64 # number of finished items
Worker(nr, input, output, dist, perform) = new(nr, input, output, dist, 1/perform, 0)
end… and a function representing their operation. The buffers are represented by channels. Then we build the system by creating workers and connecting them by channels. We start the work processes with their respective data and run the simulation.
stats(t::Float64, nr::Int64, len::Int64) = push!(df, (t, nr, len)) ## write buffersize to dataframe
function work(clk::Clock, w::Worker, stat::Bool)
job = take!(w.input)
stat ? stats(tau(clk), w.nr, length(w.input.data)) : nothing
delay!(clk, rand(w.dist) * w.retard)
put!(w.output, job)
stat ? stats(tau(clk), w.nr+1, length(w.output.data)) : nothing
w.done += 1
end
resetClock!(𝐶)
Random.seed!(1234) # seed random number generator
df = DataFrame(time=Float64[], channel=Int[], length=Int[])
C = [Channel{Int64}(Inf) for i in 1:6] # create 6 channels
j = reverse(Array(1:8))
for i in 5:-1:2 # seed channels 2:5 each with 2 inventory items
put!(C[i], j[(i-1)*2])
put!(C[i], j[(i-1)*2-1])
end
for i in 9:1000 # put other 992 jobs into channel 1
put!(C[1], i)
end
W = [Worker(i, C[i], C[i+1], Uniform(0.5, 6.5), 1.0) for i in 1:5]
for i in 1:5
process!(Prc(i, work, W[i], true))
end
run!(𝐶, 1000)"run! finished with 1390 clock events, 0 sample steps, simulation time: 1000.0"length(C[6].data) # how much got produced?2721000/2723.676470588235294After running for 1000 time units, we got 272 finished items in channel 6, meaning an average cycle time of 3.68, not 3.5 as expected. The expected throughput would have been 286 units, so the line produced only 95% of that, even under "perfect" conditions like unlimited supply, an in-process inventory to start with, infinite buffer sizes, a perfectly balanced line and equally performing workers without breaks … What happened?
using Plots
function inventory_plot(n::Int64, title)
for i ∈ 2:n
d = df[df.channel .== i, :]
doplot = i == 2 ? plot : plot!
doplot(d.time, d.length, label="channel$i")
end
title!(title)
xlabel!("time")
ylabel!("Inventory")
end
inventory_plot(5, "In-Process-Inventory of Dice-Line")
We see that statistical fluctuations in processing times (the dice!) lead to wildly fluctuating buffers, overproduction of worker 1 (look at channel 2) and also to starvation of other workers down the line when their input buffers are empty. Let's calculate the inventory of unfinished goods in the line at the end of the simulation run:
1000-length(C[1].data)-length(C[6].data)26This gives an average of 6.5 inventory items in channels 2-5. But as we see in the plot, some channels are often empty, leading to some starvation.
Parametrizing the model
For further investigations we parametrize our model. This is not easily done in graphically oriented simulators, but we can do it with DiscreteEvents.jl.
As parameters we take:
n: the length of the line (number of workers)mw: max WIP-buffer sizes (WIP is work in progress),vp: variation in processing times from item to item and,vw: variation between worker performance,d: the duration of the simulation run
We give each simulation its own clock and channels variables so that it can be run in parallel on different threads.
function dice_line( n::Int64, mw::Int64,
vp::Distribution, vw::Distribution;
d=1000, seed=1234, jobs=1000, stat::Bool=true )
clk = Clock()
Random.seed!(seed) # seed random number generator
stat ? ( global df = DataFrame(time=Float64[], channel=Int[], length=Int[]) ) : nothing
C = [Channel{Int64}(mw) for i in 1:n+1] # create n+1 channels with given buffer sizes
C[1] = Channel{Int64}(Inf) # unlimited sizes for channels 1 and n+1
C[n+1] = Channel{Int64}(Inf)
j = reverse(Array(1:(n-1)*2))
for i in n:-1:2 # seed channels 2:(n-1) each with 2 inventory items
C[i].sz_max > 0 ? put!(C[i], j[(i-1)*2]) : nothing
C[i].sz_max > 1 ? put!(C[i], j[(i-1)*2-1]) : nothing
end
for i in ((n-1)*2+1):jobs # put other jobs into channel 1
put!(C[1], i)
end
wp = rand(vw, n) # calculate worker performance
W = [Worker(i, C[i], C[i+1], vp, wp[i]) for i in 1:n]
for i in 1:n
process!(clk, Prc(i, work, W[i], stat))
end
info = run!(clk, d)
return (info, clk.evcount, length(C[end].data))
enddice_line (generic function with 1 method)Kanban …
Against too much inventory we have Kanban. So let's introduce maximum buffer sizes of 5 items. We have yet our five perfect workers without varying performance.
using Printf
info, ev, res = dice_line(5, 5, Uniform(0.5, 6.5), Normal(1,0))
println(info)
println(res, " items produced!")
@printf("%5.2f%s capacity utilization", 3.5*res/10, "%")run! finished with 1341 clock events, 0 sample steps, simulation time: 1000.0
266 items produced!
93.10% capacity utilizationUups! We throttled our system further, to an output of 266.
inventory_plot(5, "In-Process-Inventory of kanbanized Dice-Line")
But we got much less inventory in the system. The throttling occurs because with Kanban in-process-inventories get more often to zero. Seemingly Kanban is no solution for our throughput problem but constrains the system further. With Kanban we have reduced unpredictability and instability in inventory.
Let's pause a moment to look at what we have here: we got a small model with which we can simulate and analyze the impact of dependencies (line length and buffer sizes) and statistical fluctuations (in processing time and worker performance) on simple assembly lines like there are thousands in industry. This is no minor achievement.
Investigating assembly lines
With the parametrized model we can do some investigations into the behaviour of assembly lines.
For that we take first some further simplification steps:
- We normalize the model by assuming a mean processing time of 1.
- We choose a gamma distribution as more realistic for processing times than the uniform distribution, we used until now following Goldratt's example:
using StatsPlots, LaTeXStrings
for i in [2,3,5,10,15,20]
doplot = i == 2 ? plot : plot!
doplot(Gamma(i, 1/i), label=latexstring("a=$i, \\theta=$(round(1/i, digits=2))"))
end
xlabel!(L"\mathsf{processing\, time}")
ylabel!(L"\mathsf{probability\, density}")
title!(latexstring("\\mathsf{Gamma\\, distribution,\\,} \\mu=1"))
@time info, ev, res = dice_line(5, 5, Gamma(10,1/10), Normal(1,0))
println(info)
println(res, " items produced!")
@printf("y = %5.3f [1/t]", res/1000) 0.498770 seconds (560.02 k allocations: 25.146 MiB, 2.80% gc time)
run! finished with 4847 clock events, 0 sample steps, simulation time: 1000.0
966 items produced!
y = 0.966 [1/t]inventory_plot(5, "In-Process-Inventory of kanbanized Dice-Line")
Before we go deeper into parameters, we have to check how much path dependence and statistical fluctuations vary the outcome. Therefore we repeat the simulation 30 times with different random number seeds and analyze the distribution of the outcome. As outcome we choose the throughput rate y [1/t] which is also an indicator for line performance.
Random.seed!(1234)
s = abs.(rand(Int, 30))
tc = ones(30)
Threads.@threads for i = 1:30
info, ev, res = dice_line(5, 5, Gamma(10,1/10), Normal(1,0), seed=s[i], jobs=1200, stat=false)
tc[i] = res*0.001
end
ys = (μ=mean(tc), σ=std(tc))
@printf("μ: %5.3f, σ: %5.3f, LCL: %5.3f, UCL: %5.3f\n", ys.μ, ys.σ, ys.μ-3ys.σ, ys.μ+3ys.σ)
plot(1:30, tc, title="throughput rate of various runs of dice line", xlabel="runs",
ylabel="y [1/t]", legend=:none, lw=2)
hline!([ys.μ, ys.μ-3ys.σ, ys.μ+3ys.σ], lc=:red)μ: 0.967, σ: 0.005, LCL: 0.952, UCL: 0.983
Experimental design
Our response variable y seems to be under statistical control and its fluctuation is of the same order as the effects we are after. But with an experimental design those fluctuations should cancel out. We setup it up with:
n: number of workers, line length,b: buffersize between workers,a: shape parameter of gamma distribution of processing times (bigger a means less variation),σ: standard deviation of performance variation between workers.
using StatsModels, ExperimentalDesign
n = vcat(5:10,12:2:20)
b = 1:10
a = vcat(2,3,5:5:20)
σ = LinRange(0,0.1,5)
D = FullFactorial((n=n, b=b, a=a, σ=σ), @formula(y ~ n + b + a + σ), explicit = true)
size(D.matrix)(3300, 4)We got a design matrix with 3300 rows for 3300 simulations! Let's do something else while the computer works:
y = zeros(3300)
events = 0
t = @elapsed begin
Threads.@threads for i = 1:3300
p = Tuple(D.matrix[i, :])
info, ev, res = dice_line(p[1], p[2], Gamma(p[3], 1/p[3]), Normal(1, p[4]), jobs=1200, stat=false )
y[i] = res*0.001
global events += ev
end
end
@printf("Time elapsed: %5.2f minutes, %d events on %d threads", t/60, events, Threads.nthreads())Time elapsed: 1.42 minutes, 33556453 events on 8 threadsIt takes 1.4 minutes on 8 threads of a 2019 MacBook Pro and over $33\times 10^6$ events.
Data analysis
We put together a results table and do some exploratory data analysis:
res = D.matrix
res.y = y
describe(y)Summary Stats:
Length: 3300
Missing Count: 0
Mean: 0.892545
Minimum: 0.638000
1st Quartile: 0.864000
Median: 0.904000
3rd Quartile: 0.937000
Maximum: 0.986000
Type: Float64The performance of our simulated assembly lines varies between 0.637 and 0.986, which is a huge difference: The worst result is 35.8% below the best one!
vcat(res[y .== maximum(y), :], res[y .== minimum(y), :])| no | n | b | a | σ | y |
|---|---|---|---|---|---|
| 1 | 6 | 7 | 20 | 0.0 | 0.986 |
| 2 | 5 | 10 | 20 | 0.0 | 0.986 |
| 3 | 20 | 1 | 2 | 0.1 | 0.638 |
The best performance is with the shortest lines, big buffer sizes, small variation in processing times and no variation in performance between workers. But this is just common sense. The worst performance is with a long line, minimum buffers and maximum variation in processing times and in performance between workers. But how big are the effects?
@df res dotplot(:n, :y, title="line performance vs line length", xlabel="n", ylabel="y [1/t]",
marker=(:circle, 2, 0.3, :none, 1, 0.3, :blue, :solid), legend=:none)
@df res boxplot!(:n, :y, marker=(:none, 0.3, 0.3, :blue, 2, 0.3, :blue, :solid), fill=(0, 0.2, :blue))
@df res dotplot(:b, :y, title="line performance vs buffer size", xlabel="b", ylabel="y [1/t]",
marker=(:circle, 2, 0.3, :none, 1, 0.3, :blue, :solid), legend=:none)
@df res boxplot!(:b, :y, marker=(:none, 0.3, 0.3, :blue, 2, 0.3, :blue, :solid), fill=(0, 0.2, :blue))
@df res dotplot(:a, :y, title="line performance vs processing time variation", xlabel="a (bigger a: less variation)",
ylabel="y [1/t]", marker=(:circle, 2, 0.3, :none, 1, 0.3, :blue, :solid), legend=:none)
@df res boxplot!(:a, :y, marker=(:none, 0.3, 0.3, :blue, 2, 0.3, :blue, :solid), fill=(0, 0.2, :blue))
x = Int.(round.(res.σ*40))
@df res dotplot(x, :y, title="line performance vs worker performance variation", xlabel=L"\sigma", ylabel="y [1/t]",
marker=(:circle, 2, 0.3, :none, 1, 0.3, :blue, :solid), legend=:none)
@df res boxplot!(x, :y, marker=(:none, 0.3, 0.3, :blue, 2, 0.3, :blue, :solid), fill=(0, 0.2, :blue))
xticks!(collect(0:4), string.(round.(σ, digits=3)))
Buffer sizes and variation in processing time clearly have nonlinear effects while line length and performance variation between workers seem to have more linear ones. Small buffers and variation in processing time constrain the line the most and also are responsible for the worst performances. There seems to be also an interaction between those major two factors.
Statistical model
We fit a linear model to the results and account for the nonlinearities with logarithmic terms:
using GLM
ols = lm(@formula(y ~ 1 + n + log(1+b) + log(a) + σ), res)StatsModels.TableRegressionModel{LinearModel{GLM.LmResp{Array{Float64,1}},GLM.DensePredChol{Float64,LinearAlgebra.Cholesky{Float64,Array{Float64,2}}}},Array{Float64,2}}
y ~ 1 + n + :(log(1 + b)) + :(log(a)) + σ
Coefficients:
────────────────────────────────────────────────────────────────────────────────
Coef. Std. Error t Pr(>|t|) Lower 95% Upper 95%
────────────────────────────────────────────────────────────────────────────────
(Intercept) 0.738062 0.00234884 314.22 <1e-99 0.733457 0.742667
n -0.00155442 9.8016e-5 -15.86 <1e-53 -0.0017466 -0.00136225
log(1 + b) 0.057606 0.000896342 64.27 <1e-99 0.0558486 0.0593634
log(a) 0.0509241 0.000563634 90.35 <1e-99 0.049819 0.0520292
σ -0.509952 0.0133361 -38.24 <1e-99 -0.536099 -0.483804
────────────────────────────────────────────────────────────────────────────────All parameters are highly significant. We find then - as expected - that the b&a-interaction between buffer size and variation in processing times is highly significant too:
ols2 = lm(@formula(y ~ 1 + n + log(1+b)*log(a) + σ), res)StatsModels.TableRegressionModel{LinearModel{GLM.LmResp{Array{Float64,1}},GLM.DensePredChol{Float64,LinearAlgebra.Cholesky{Float64,Array{Float64,2}}}},Array{Float64,2}}
y ~ 1 + n + :(log(1 + b)) + :(log(a)) + σ + :(log(1 + b)) & :(log(a))
Coefficients:
───────────────────────────────────────────────────────────────────────────────────────
Coef. Std. Error t Pr(>|t|) Lower 95% Upper 95%
───────────────────────────────────────────────────────────────────────────────────────
(Intercept) 0.599288 0.00313879 190.93 <1e-99 0.593134 0.605442
n -0.00155442 7.20551e-5 -21.57 <1e-95 -0.0016957 -0.00141315
log(1 + b) 0.136895 0.00163616 83.67 <1e-99 0.133687 0.140103
log(a) 0.123915 0.00143956 86.08 <1e-99 0.121092 0.126737
σ -0.509952 0.00980384 -52.02 <1e-99 -0.529174 -0.490729
log(1 + b) & log(a) -0.0417033 0.00078769 -52.94 <1e-99 -0.0432478 -0.0401589
───────────────────────────────────────────────────────────────────────────────────────Then we can analyze the effects of the four parameters on line performance:
x = LinRange(1,10,50)
for i in reverse(a)
_n = fill(mean(n), length(x))
_a = fill(i, length(x))
_σ = fill(mean(σ), length(x))
tmp = DataFrame(n=_n, b=x, a=_a, σ=_σ)
_y = predict(ols2, tmp)
doplot = i == 20 ? plot : plot!
doplot(x, _y, label="a=$i")
end
title!("Effects of buffer size and processing time variation", legend=:bottomright)
xlabel!("b (buffer size)")
ylabel!("y [1/t]")
Buffer size and processing time variation have nonlinear effects and may account together for 26% line performance losses. This shows how important it is to increase buffer sizes with larger variation in processing times (smaller a). Only with small variation one can reduce buffers without loosing much performance.
x = LinRange(5, 20, 50)
tmp = DataFrame(n=x, b=fill(mean(b), length(x)), a=fill(mean(a), length(x)),
σ=fill(mean(σ), length(x)))
plot(x, predict(ols2, tmp), title="Effect of line length", xlabel="n (line length)",
ylabel="y [1/t]", legend=:none)
This may account for 3% performance losses.
x = LinRange(0,0.1,50)
tmp = DataFrame(n=fill(mean(n), length(x)), b=fill(mean(b), length(x)),
a=fill(mean(a), length(x)), σ=x)
plot(x, predict(ols2, tmp), title="Effect of performance variation between workers",
xlabel=L"\sigma", ylabel="y [1/t]", legend=:none)
Variation in performance between workers may diminish line throughput by other 5%.
The four effects combined can account for 34% performance losses from best to worst. This is most of the 35.8% we found above. The rest is mostly statistical fluctuations.
Final remark
Starting from a simple game and with only a quite small simulation model we could come to conclusions with a wide applicability for assembly lines. The performance differences in assembly lines are realistic – I have seen them over and over in industry. And we didn't yet account for failures or supply shortfalls. The unawareness of those simple factors costs manufacturing industry billions.
The most interesting thing to note here is, that from seemingly quite unpredictable behaviour – look at the inventory chart of the beginning – emerge some quite predictable characteristics out of multiple discrete event simulations with parameter variation combined with some not too sophisticated statistics.
We could not have done those experiments and analyses with real lines as it is possible with simulations on a modern computer with Julia and DiscreteEvents.jl.